En mai dernier, j’avais retweeté cette comparaison que j’aime beaucoup (traduite par mes soins) :
Une interface utilisateur, c’est comme une blague. Si vous devez l’expliquer, c’est qu’elle n’est pas si bonne.
La citation a été reprise en français (sans mention de l’auteur original, tant pis), mais avec une légère déformation au passage :
Une interface utilisateur, c’est comme une blague, s’il faut l’expliquer c’est qu’elle n’est pas bonne.
Cette déperdition dans la traduction a généré quelques débats intéressants ici ou là. Et si je suis le premier à détester les explications pour utiliser une porte et à préférer l’apprentissage par le design, je sais aussi reconnaître que la complexité est parfois nécessaire.
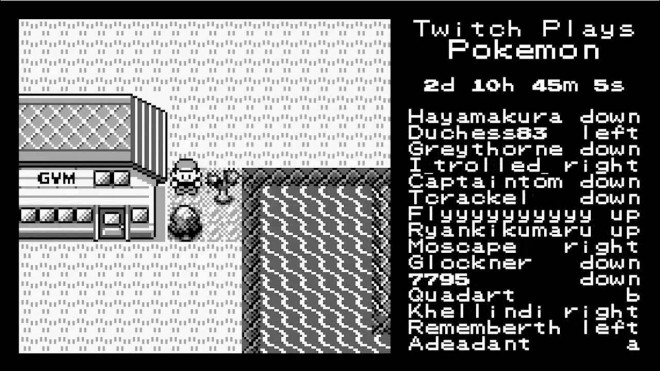
Prenons par exemple le tableau de bord d’un Airbus A380.

Au premier abord, pour le néophyte que je suis, cette interface me paraît atrocement compliquée. Mais c’est peut-être parce que je n’y connais absolument rien en aviation. Et cette interface est destinée à être utilisée par des professionnels, ayant suivi des années de formations spécifiques. En soi, c’est plutôt rassurant de se dire que l’interface d’un appareil servant à transporter 800 personnes dans les airs est incompréhensible pour le premier venu.
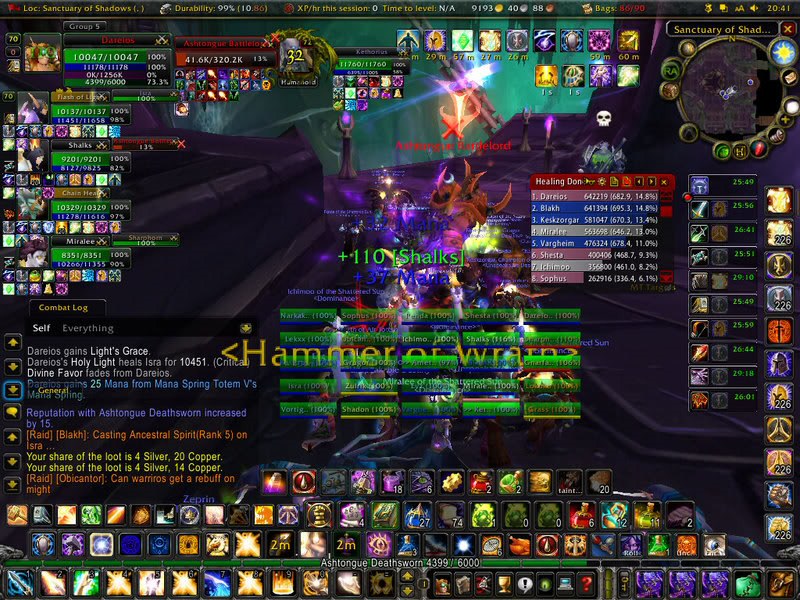
Je pourrais en dire de même pour les interfaces des logiciels de traders ou même l’interface de World of Warcraft. Mais ces remarques sur les interfaces sont aussi valables pour les blagues.
Voici une de mes blagues préférées découverte ces dernières années (catégorisée dans les « blagues de papas »).
— Call me a taxi.
— OK. You’re a taxi.
Au risque de passer pour un idiot, je n’avais pas compris cette blague à sa première lecture. Mais dès que je l’ai comprise, j’ai trouvé ça drôle. C’est une bonne blague. La même chose est valable pour la blague anglophone suivante, lue chez Bruce Lawson :
Jean-Pierre : Toc-toc.
Armand : Qui est là ?
Jean-Pierre : Loste.
Armand : Loste qui ?
Jean-Pierre : Oui, malheureusement.
J’ai dû chercher des explications pour comprendre cette blague. Ça ne signifie pas que c’est une mauvaise blague. Maintenant que je la comprends, je l’apprécie beaucoup.
Une interface utilisateur, c’est comme une blague. Certaines blagues sont compréhensibles instantanément. D’autres nécessitent des explications pour être comprises par des gens comme moi qui pourront ensuite la trouver drôle. Mais ça ne suffit pas pour déterminer si une interface est bonne ou pas.

{kind=link}
{kind=link}